机器学习-朴素贝叶斯分类
最后更新时间:
文章总字数:
预计阅读时间:
朴素贝叶斯分类
一.贝叶斯分类理论
现在用p1(x,y)表示数据点(x,y)属于类别1的概率,用p2(x,y)表示数据点(x,y)属于类别2的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
如果p1(x,y)> p2(x,y),那么类别为1
如果p1(x,y)< p2(x,y),那么类别为2
也就是说,选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
二.条件概率
条件概率,就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
根据文氏图,在事件B发生的情况下,事件A发生的概率就是
𝑃(𝐴|𝐵)=𝑃(𝐴∩𝐵)/𝑃(𝐵)
因此,
𝑃(𝐴∩𝐵)=𝑃(𝐴|𝐵)𝑃(𝐵)
同理可得,
𝑃(𝐴∩𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)
即
𝑃(𝐴|𝐵)=𝑃(B|A)𝑃(𝐴)/𝑃(𝐵)
这就是条件概率的计算公式。
三.全概率公式
如图:
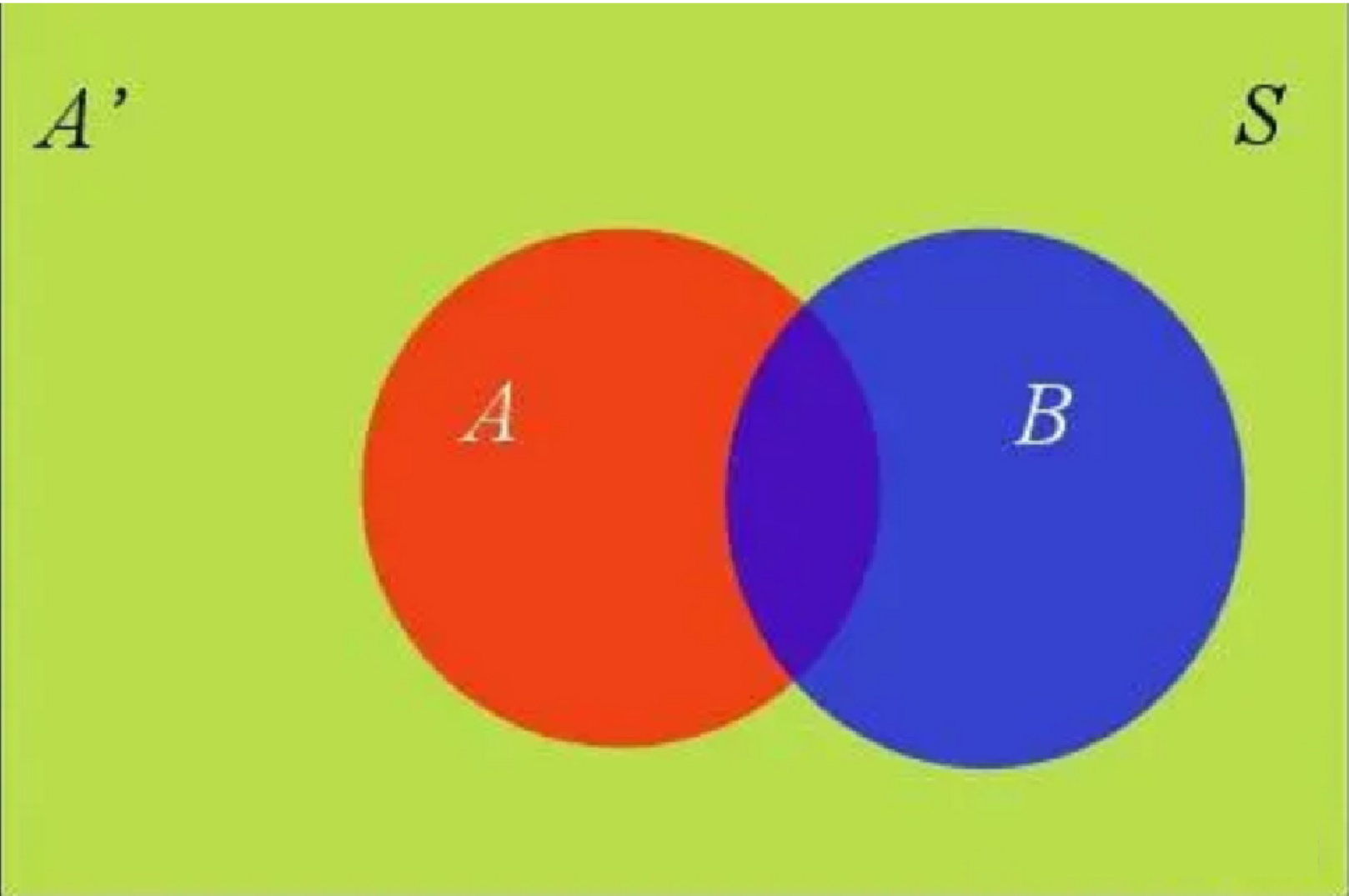
𝑃(𝐵)=𝑃(𝐵∩𝐴)+𝑃(𝐵∩𝐴′)
在上面的推导当中,我们已知
𝑃(𝐵∩𝐴)=𝑃(𝐵|𝐴)𝑃(𝐴)
所以:
𝑃(𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)+𝑃(𝐵|𝐴′)𝑃(𝐴′)
这就是全概率公式。它的含义是,如果A和A’构成样本空间的一个划分,那么事件B的概率,就等于A和A’的概率分别乘以B对这两个事件的条件概率之和。
四.贝叶斯推断
我们把P(A)称为”先验概率”(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为”后验概率”(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为”可能性函数”(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:
后验概率 = 先验概率x调整因子
五.朴素贝叶斯推断
朴素贝叶斯对条件概率分布做了条件独立性的假设,也就是把单个特征之间的计算变成了多个特征。
根据贝叶斯定理,后验概率 P(a|X) 可以表示为:
其中:
- P(X|a) 是给定类别 ( a ) 下观测到特征向量 X=(x1, x2, …, xn)的概率;
- P(a) 是类别 a 的先验概率;
- P(X) 是观测到特征向量 X 的边缘概率,通常作为归一化常数处理。
我们可以将联合概率 P(X|a) 分解为各个特征的概率乘积:
下面有一个例子方便进行理解:
示例:
P(好瓜)=(好瓜数量)/所有瓜
P(坏瓜)=(坏瓜数量)/所有瓜
p(纹理清晰)=(纹理清晰数量)/所有瓜
p(好瓜|纹理清晰,色泽清绿,鼓声沉闷)
=【p(好瓜)】【p(纹理清晰,色泽清绿,鼓声沉闷|好瓜)】/【p(纹理清晰,色泽清绿,鼓声沉闷)】
=【p(好瓜)】【p(纹理清晰|好瓜)p(色泽清绿|好瓜)p(鼓声沉闷|好瓜)】/【p(纹理清晰)p(色泽清绿)p(鼓声沉闷)】
p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷)
=【p(坏瓜)p(纹理清晰|坏瓜)p(色泽清绿|坏瓜)p(鼓声沉闷|坏瓜)】/【p(纹理清晰)p(色泽清绿)*p(鼓声沉闷)】
从公式中判断”p(好瓜|纹理清晰,色泽清绿,鼓声沉闷)”和”p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷)”时,因为它们的分母
值是相同的,所以只要计算它们的分子就可以判断是”好瓜”还是”坏瓜”之间谁大谁小了,所以没有必要计算分母
p(好瓜) = 6/10
p(坏瓜)=4/10
p(纹理清晰|好瓜) = 4/6
p(色泽清绿|好瓜) = 4/6
p(鼓声沉闷|好瓜) = 2/6
p(纹理清晰|坏瓜) = 1/4
p(色泽清绿|坏瓜) = 1/4
p(鼓声沉闷|坏瓜) = 1/4
把以上计算代入公式的分子
p(好瓜)p(纹理清晰|好瓜)p(色泽清绿|好瓜)p(鼓声沉闷|好瓜) = 4/45
p(坏瓜)p(纹理清晰|坏瓜)p(色泽清绿|坏瓜)p(鼓声沉闷|坏瓜) = 1/160
所以
p(好瓜|纹理清晰,色泽清绿,鼓声沉闷) > p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷),
所以把(纹理清晰,色泽清绿,鼓声沉闷)的样本归类为好瓜
六.拉普拉斯平滑系数
某些事件或特征可能从未出现过,这会导致它们的概率被估计为零,拉普拉斯平滑技术可以避免这种“零概率陷阱”,
其公式为:
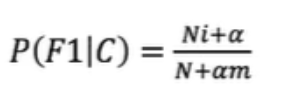
一般α取值1,m的值为总特征数量
API
sklearn.naive_bayes.MultinomialNB(alpha=1)
- alpha: 默认为1
1 | |
结果:
1 | |