机器学习-岭回归与Lasso回归
最后更新时间:
文章总字数:
预计阅读时间:
一.岭回归 Ridge
岭回归是失损函数通过添加所有权重的平方和的乘积(L2)来惩罚模型的复杂度。公式如下:
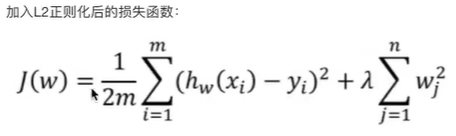
已经定死使用L2正则化后函数(MSE + L2)
特点:
岭回归不会将权重压缩到零,这意味着所有特征都会保留在模型中,但它们的权重会被缩小。
适用于特征间存在多重共线性的情况。
岭回归产生的模型通常更为平滑,因为它对所有特征都有影响。
这里的API直接用就可以,要使用小批量的话,替代SGD函数就好。
API:
sklearn.linear_model.Ridge()
参数:
alpha, default=1.0,正则项力度
fit_intercept, 是否计算偏置, default=True
solver, {‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, default=’auto’
当值为auto,并且数据量、特征都比较大时,内部会随机梯度下降法。normalize:,default=True, 数据进行标准化,如果特征工程中已经做过标准化,这里就该设置为False
max_iterint, default=None,梯度解算器的最大迭代次数,默认为15000
属性:
coef_ 回归后的权重系数
intercept_ 偏置
说明:SGDRegressor也可以做岭回归的事情,比如SGDRegressor(penalty=’l2’,loss=”squared_loss”),但是其中梯度下降法有些不同。所以推荐使用Ridge实现岭回归
1 | |
结果:
1 | |
二.拉索回归 lasso
Lasso回归是一种线性回归模型,它通过添加所有权重的绝对值之和(L1)来惩罚模型的复杂度。公式如下:
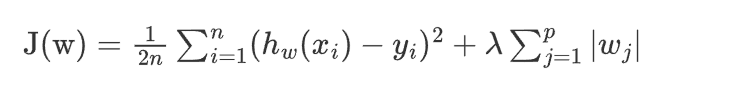
定死使用L1正则化后函数(MAE + L1)
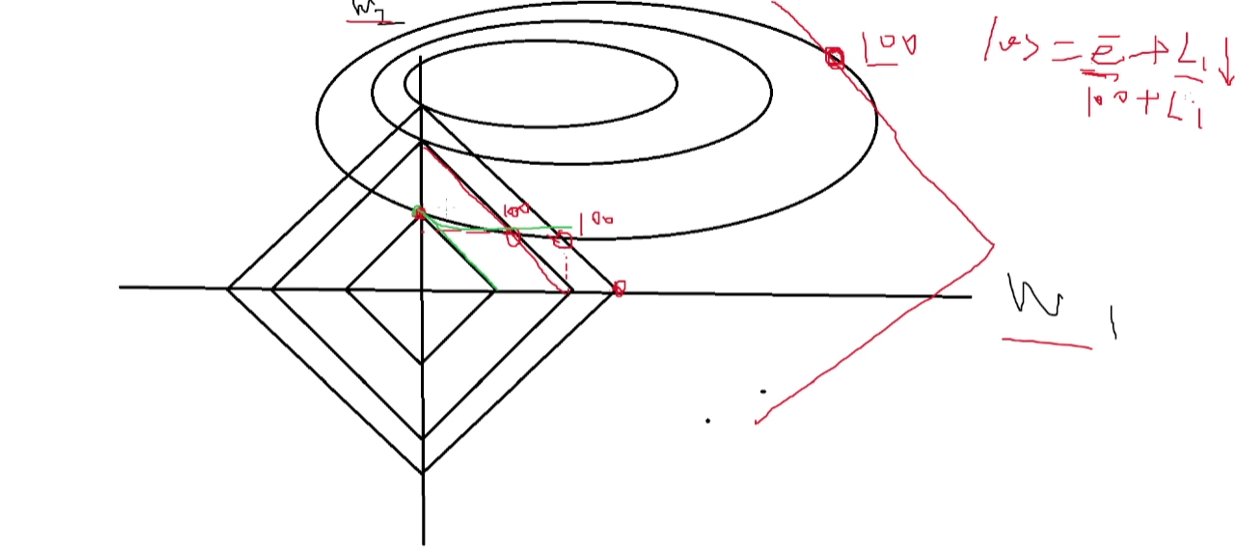
可以看到,lasso回归进行正则化的原理实际也是在同等损失下,让惩罚性更小,这个取值的点一般都在坐标轴上,因为此时惩罚项是最小的。但是我们实际的目的是让loss下降,所以在w的取舍下,会优先考虑让损失下降,而非先考虑惩罚性的下降(loss的数量级更高)。不过即使这样考虑,损失依然会有一些上升,这是考虑正则项的必然。
这里的API直接用就可以,要使用小批量的话,替代SGD函数就好。
API:
sklearn.linear_model.Lasso()
参数:
alpha (default=1.0):控制正则化强度,非负浮点数。
fit_intercept (default=True):是否计算此模型的截距。
precompute (bool or array-like, default=False):
如果为 True,则使用预计算的 Gram 矩阵来加速计算。如果为数组,则使用提供的 Gram 矩阵。
copy_X (default=True):如果为 True,则复制数据 X,否则可能对其进行修改。
max_iter (default=1000):最大迭代次数。
tol (float, default=1e-4):精度阈值。如果更新后的系数向量减去之前的系数向量的无穷范数除以 1,加上更新后的系数向量的无穷范数小于 tol,则认为收敛。
warm_start (bool, default=False):为 True 时,再次调用 fit 方法会重新使用之前调用 fit 方法的结果作为初始估计值
positive (bool, default=False):为 True 时,强制系数为非负。
random_state:随机数种子
selection ({‘cyclic’, ‘random’}, default=’cyclic’):
如果设置为 ‘random’,则随机选择坐标进行更新。如果设置为 ‘cyclic’,则按照循环顺序选择坐标。
属性:
coef_
- 系数向量或者矩阵,代表了每个特征的权重。
intercept_
- 截距项(如果 fit_intercept=True)。
n_iter_
- 实际使用的迭代次数。
n_features_in_ (int):
- 训练样本中特征的数量。
注意:w是可以比x特征数量多的。比如
1 | |
这就是非线性回归。
1 | |