机器学习-sklearn梯度下降
最后更新时间:
文章总字数:
预计阅读时间:
sklearn 梯度下降
官方的梯度下降API常用有三种:
批量梯度下降BGD(Batch Gradient Descent)
小批量梯度下降MBGD(Mini-BatchGradient Descent)
随机梯度下降SGD(Stochastic Gradient Descent)。
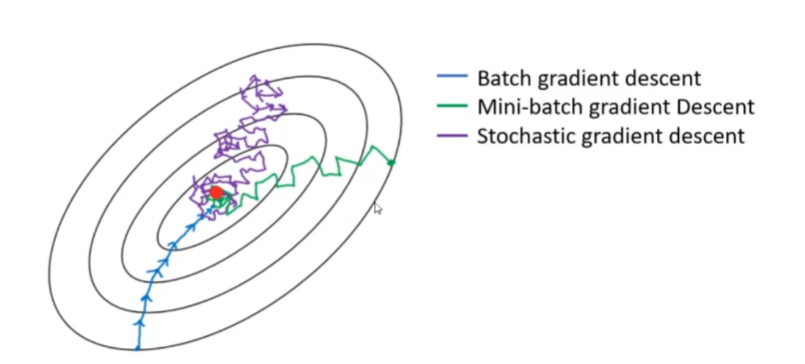
上面的图中,描述的正是三种梯度下降算法实现的过程,黑色等高线代表损失。接下来我们详细讲讲:
一.批量梯度下降BGD
其使用整个训练数据集来计算梯度并更新模型参数,这也就是我们之前用的算法。每一次迭代都使用所有数据来进行训练(构建损失函数),这使得更新方向更加准确,但计算成本较高,且一个很大的缺点是需要在内存中存储整个数据集,对于大型数据集来说可能成为一个问题。
而且BGD是没有专门的API函数的,所以只能自己实现,包括损失函数的计算,梯度的计算以及权重更新的代码都要自己写。
二.随机梯度下降SGD
每一步更新参数时,仅使用单个训练样本,用这个样本计算梯度,然后更新参数w,直到一轮训练epoch完成,即整个数据集被遍历完一次。
每一次更新用的都是上一个样本更新的w,来计算这一次选择的样本的梯度,然后再更新w。
后期能够很好地解决局部最优解的问题。然而,由于每次只使用一个样本进行更新,梯度估计可能较为嘈杂,这可能导致更新过程中出现较大的波动。在实际应用中,可以通过减少学习率(例如采用学习率衰减策略)来解决。
注意:
学习率 alpha: 需要适当设置,太大会导致算法不收敛,太小则收敛速度慢。
随机性: 每次迭代都从训练集中随机选择一个样本,这有助于避免陷入局部最小值。
停止条件: 可以是达到预定的最大迭代次数,或者梯度的范数小于某个阈值。
API:
sklearn.linear_model.SGDRegressor()
参数:
loss: 损失函数,默认为 squared_error
fit_intercept: 是否计算偏置,default=True
eta0:学习率初始值,默认0.01
learning_rate:
- constant: eta = eta0 学习率为eta0设置的值,保持不变
下面的三种都是让学习率不断减小,只是公式不同:
- optimal: eta = 1.0 / (alpha * (t + t0))
- invscaling(默认): eta = eta0 / pow(t, power_t)
- adaptive: eta = eta0, 学习率由eta0开始,逐步变小
max_iter: 取数据的次数,default=1000
shuffle=True 每批次是否洗牌
penalty(暂时不用管):要使用的惩罚(又称正则化项)
默认为’ l2 ‘,这是线性SVM模型的标准正则化器。
‘ l1 ‘和’ elasticnet ‘可能会给模型(特征选择)带来’ l2 ‘无法实现的稀疏性。
当设置为None时,不添加惩罚。
属性:
coef_ 回归后的权重系数
intercept_ 偏置
1 | |
结果:
1 | |
三.小批量梯度下降MBGD
小批量梯度下降是一种介于批量梯度下降(BGD)与随机梯度下降(SGD)之间的优化算法,它结合了两者的优点,在机器学习和深度学习中被广泛使用。
基本思想是在每个迭代步骤中使用一小部分(即“小批量”)训练样本来计算损失函数的梯度,并据此更新模型参数。小批量梯度下降能够在保持较快的收敛速度的同时,维持相对较高的稳定性。且MBGD和SGD都有几个优点:
减少内存需求
可以进行分布式训练:因为一般数据集很大,数据都是存在磁盘中,每次使用取一部分出来。只取一条或者一批数据方便几台电脑同时训练一个大数据集
在线学习:可以随时训练,即使用原数据开始训练时,另一个新的数据集也可以加入训练中
但由于没有BGD的API,所以只能用SGD来实现。但严格来说这样实现的也不是MBGD的算法思想,而是另一种接近的思想。
注意:我们分批次(batch)地训练模型,调用partial_fit函数训练会直接更新权重,而不需要调fit从头开始训练。
fit()是不用自己设置迭代次数的,max_iter就能控制迭代次数。而partial_fit()每次只能训练一批数据,迭代需要自己实现,max_iter不起作用。所以每一批次的训练需要自己来用for循环实现,所有批次遍历完就是一个epoch。只使用SGD的话,也就是使用fit会使用其中默认的batch_size=1,即每次迭代训练一个样本。
1 | |
以后梯度下降都是用的MBGD方法,且上面的代码就是机器学习及深度学习的基本步骤。
四.梯度下降优化
4.1 标准化
针对数据方面的问题优化
4.2 正则化
针对模型方面的问题优化,把模型变简单