机器学习-无量纲化与特征降维(一)
最后更新时间:
文章总字数:
预计阅读时间:
一.无量纲化-预处理无量纲,即没有单位的数据
无量纲化包括”归一化”和”标准化”,这样做有什么用呢?假设用欧式距离计算一个公司员工之间的差距,有身高(m)、体重(kg)以及收入(元)三个标准,正常情况下,收入带来的差距会很大,且看下面的公式:

从计算上来看, 发现身高体重对计算结果没有什么影响, 基本主要由收入来决定了,但是现实生活中,身高是比较重要的判断标准. 所以需要无量纲化.
1.1 MinMaxScaler 归一化
公式:
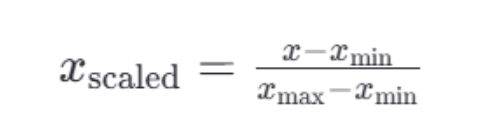
API:
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:
- feature_range:归一化后的数据的范围,默认为(0,1)。归一化中假设x是(0,1),设置为(2,5)背后即用x*(5-2)+2就可以完成归一化后的范围转化。
返回值为ndarray类型
1 | |
结果:
1 | |
1.2 normalize归一化
API:
normalize(data, norm='l2', axis=1)
参数:
norm:归一化方式,默认为l2,可选l1、l2、max
l1:绝对值相加作为分母,特征值作为分子
l2:平方相加作为分母,特征值作为分子
max:最大值作为分母,特征值作为分子
axis:归一化的维度,默认为1,可选0、1
返回值:归一化后的数据
1 | |
结果:
1 | |
注意:这里的normalize是不需要进行fit_transform操作的
上述两种归一化都有缺点:最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量钢化。
1.3 StandardScaler 标准化
也是数据归一化的一种,目的是将不同特征的数值范围缩放到统一的标准范围。
最常见的标准化方法是Z-score标准化,也叫零均值标准化。通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布:
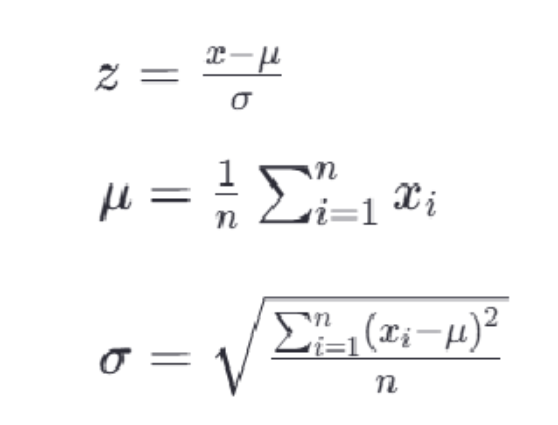
API:
sklearn.preprocessing.StandardScale
所有归一化返回的都是ndarray类型
1 | |
结果:
1 | |
这里补充讲讲前面提到过的 fit_transform() 与 fit() 和 transform() 的区别:
fit() 是对传入的数据进行计算,transform() 是对传入的数据进行特征转换,fit_transform() 是先 fit()再 transform()。
1 | |
结果:
1 | |
可以发现,上面的结果有所不同,这是因为先调用了 fit() 对data的数据进行计算,得到data的均值和方差,此时调用 transform() 会使用最近一次 fit() 计算的均值与方差,所以这里就是用data的均值和方差来对data1进行标准化处理。也可以先调 fit_transform 然后再调 transform ,就是使用前面 fit_transform 计算的均值和方差转化。
这个通常用于训练集与测试集,要用训练集中的均值和方差来对测试集进行转化,一般不使用测试集的均值方差。
二.特征降维
实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征。其目的就是减少数据集维度,尽可能保留重要信息。
有两种常见的特征降维方式:
特征选择
- 从原始特征集中挑选出最相关的特征
主成份分析(PCA)
- 主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
接下来介绍一下基本的特征选择:
2.1 特征选择
2.1.1 VarianceThreshold 低方差过滤特征选择
若一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,下面是VarianceThreshold的工作原理:
计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
过滤特征:移除所有方差低于设定阈值threshold的特征
API:
1 | |
1 | |
结果:
1 | |
2.1.2 根据相关系数的特征选择
皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量,它是一个介于-1和1之间的数。
ρ = 1 表示完全正相关,即随着一个变量的增加,另一个变量也线性增加。
ρ = -1 表示完全负相关,即随着一个变量的增加,另一个变量线性减少。
ρ = 0 表示两个变量之间不存在线性关系。
|ρ|<0.4为低度相关; 0.4<=|ρ|<0.7为显著相关; 0.7<=|ρ|<1为高度相关
API:
scipy.stats.personr(x, y)
参数:
- x, y: 数组或序列,维度必须相同或能广播至相同。
返回对象有两个属性:
statistic 皮尔逊相关系数
pvalue 另一种相关稀疏,零假设(作了解),统计上评估两个变量之间的相关性,越小越相关
1 | |
结果:
1 | |