机器学习-k-means聚类算法
最后更新时间:
文章总字数:
预计阅读时间:
无监督学习-k-means聚类算法
一.特点
数据集中,拥有数据特征,但是没有具体的标签
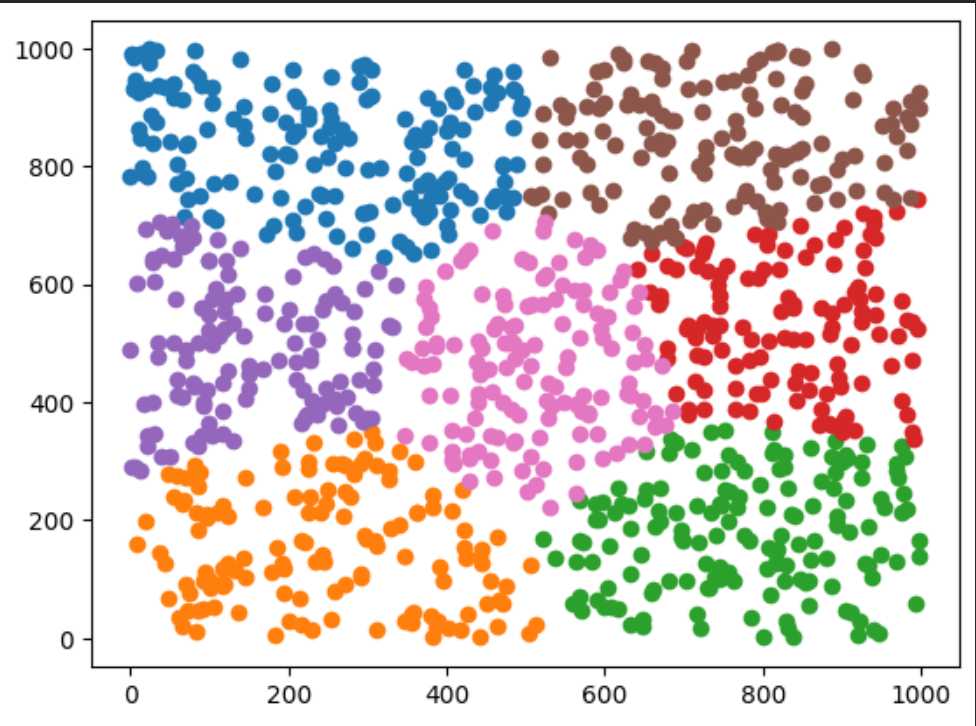
将数据划分成有意义或有用的簇
聚类算法追求“簇内差异小,簇外差异大”。而这个 “差异”便是通过样本点到其簇质心的距离来衡量
二.k-means算法
2.1 算法介绍
该算法的目标是将数据集中的样本划分为K个簇,使得簇内的样本彼此之间的差异最小化。这种差异通常通过簇内所有点到该簇中心点的距离平方和(欧式距离)来衡量。
相关概念:
簇:
Kmeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上看来簇是一个又一个聚集一起的数据,在一个簇中的数据就认为是同一类,簇就是聚类的结果表现,其中簇的个数是一个超参数质心:每个簇中所有数据的均值
u,通常被称为这个簇的"质心",在二维平面中,簇的质心横坐标是横坐标的均值,质心的纵坐标是纵坐标的均值
2.2 算法步骤
随机抽取
k个样本作为最初的质心,这可以通过随机选取数据集中的K个样本或用一些启发式方法(比如选择最远的两点)计算每个样本点与
k个质心的距离(通常是欧氏距离),将样本点分配到最近的一个质心每次聚类算法完成一次后,重新计算质心的位置,重复聚类过程
当质心的位置不再发生变化或者迭代结束,聚类完成
API
sklearn.cluster.KMeans
参数:
n_clusters: 簇的数量,默认为8。init: {‘k-means++’, ‘random’}, callable 或传入的数组,默认为’k-means++’。’k-means++’使用一种启发式方法来选择初始质心,以加快收敛速度;’random’则随机选择初始质心n_init: 运行算法的次数(epoch),每次使用不同的质心初始化。默认为10。max_iter: 单次运行的最大迭代次数,默认为300
属性:
cluster_centers_:存储每个聚类的中心点坐标,一个数组labels_:存储每个数据点的聚类标签,一个数组
make_blobs
是 Sklearn 库中 sklearn.datasets 模块提供的一个函数,用于生成一组二维或高维的数据簇。这些数据簇通常用于聚类算法的测试。
参数:
n_samples 指定生成样本的数量
centers 定义数据集中簇的中心数量,即一个簇有几个中心
random_state 随机数种子
返回值:(元组)
X:一个形状为 (n_samples, n_features) 的数组,表示生成的样本数据。每个样本都是一行,特征列为样本的各个维度坐标
y:一个形状为 (n_samples,) 的数组,表示每个样本所属的簇标签(中心索引)。如果不需要这个标签,可以像示例中那样用 _ 忽略它
1 | |
结果: