DataFrame操作(扩充)
最后更新时间:
文章总字数:
预计阅读时间:
一.合并
merge 将两个 DataFrame 对象根据一个或多个键进行合并,类似于 SQL 中的 JOIN 操作
1 | |
参数:
left:左侧的 DataFrame 对象。
right:右侧的 DataFrame 对象。
how:合并方式,可以是 ‘inner’、’outer’、’left’ 或 ‘right’。默认为 ‘inner’。
‘inner’:内连接,返回两个 DataFrame 共有的键。
‘outer’:外连接,返回两个 DataFrame 的所有键。
‘left’:左连接,返回左侧 DataFrame 的所有键,以及右侧 DataFrame 匹配的键。
‘right’:右连接,返回右侧 DataFrame 的所有键,以及左侧 DataFrame 匹配的键。
on:用于连接的列名。如果未指定,则使用两个 DataFrame 中相同的列名。
left_on 和 right_on:分别指定左侧和右侧 DataFrame 的连接列名。
left_index 和 right_index:布尔值,指定是否使用索引作为连接键。
sort:布尔值,指定是否在合并后对结果进行排序。
suffixes:一个元组,指定当列名冲突时,右侧和左侧 DataFrame 的后缀。
copy:布尔值,指定是否返回一个新的 DataFrame。如果为 False,则可能修改原始 DataFrame。
indicator:布尔值,如果为 True,则在结果中添加一个名为 __merge 的列,指示每行是如何合并的。
validate:验证合并是否符合特定的模式。
1 | |
结果:
1 | |
1 | |
结果:
1 | |
1 | |
结果:
1 | |
1 | |
结果:
1 | |
二.随机抽样
1 | |
参数:
n:要抽取的行数
frac:抽取的比例,比如 frac=0.5,代表抽取总体数据的50%
replace:布尔值参数,表示是否以有放回抽样的方式进行选择,默认为 False,取出数据后不再放回
weights:可选参数,代表每个样本的权重值,参数值是字符串或者数组
random_state:可选参数,控制随机状态,默认为 None,表示随机数据不会重复;若为 1 表示会取得重复数据
axis:表示在哪个方向上抽取数据(axis=1 表示列/axis=0 表示行)
基本理解背后思想即可,不经常使用。
1 | |
结果:
1 | |
三.空值处理
3.1 检测空值
isnull()检测 DataFrame 或 Series 中的空值,返回一个布尔值的 DataFrame 或 Series。
notnull()检测 DataFrame 或 Series 中的非空值,返回一个布尔值的 DataFrame 或 Series。
1 | |
结果:
1 | |
3.2 填充空值
fillna()
1 | |
结果:
1 | |
3.3 删除空值
dropna()
1 | |
结果:
1 | |
四.读取CSV文件
csv 介于 txt 与 excel 之间,txt 文件是纯文本文件,excel 文件是电子表格文件。
可以用记事本打开,也可以通过 excel 打开变成表格。其为 txt 时,以逗号分割列;随后用 excel打开就能看到分割的两列。
4.1 存储csv
to_csv() 方法将 DataFrame 存储为 csv。
1 | |
结果:
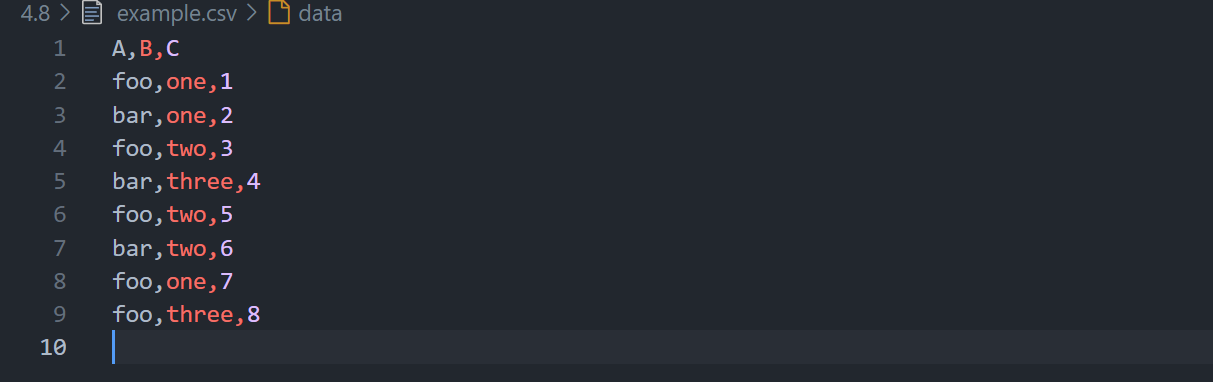
那把index传进去为什么不方便呢,来看看:
1 | |
结果:
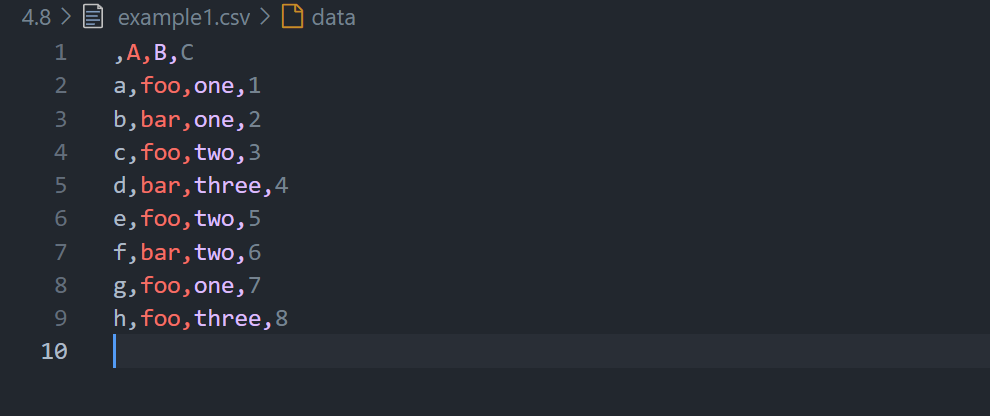
可见,列标签是在最上方的,最左边还多了一个逗号。然后依次往下看会发现很多的行标签,如果行标签是数字的话其实就可以以省略不写,因为默认就是从0开始,肉眼上会有很多重复的数字。但是如果行标签是字母的话,那么就必须要写上。
4.2 读取数据
read_csv() 将 csv 转换成 DataFram。
1 | |
结果:
1 | |
五.绘图
Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图。
只用 pandas 绘制图片可能可以编译,但是不会显示图片,需要使用 matplotlib 库,调用 show() 方法显示图形
参数:
kind:绘图类型,默认为 line,可选值有:
line:折线图
bar:柱状图
hist:直方图
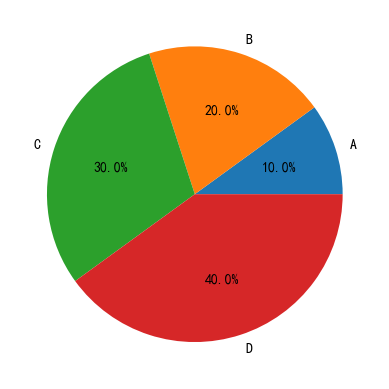
pie:饼图
scatter:散点图
1 | |
结果:
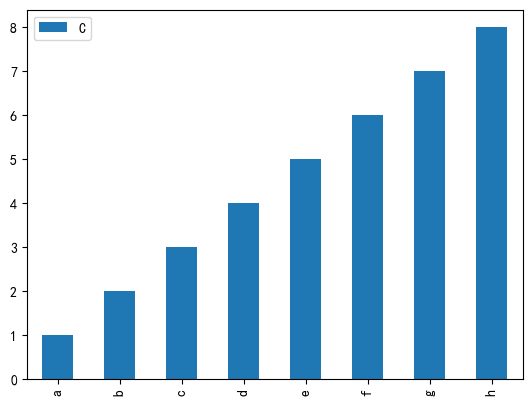
1 | |
结果:
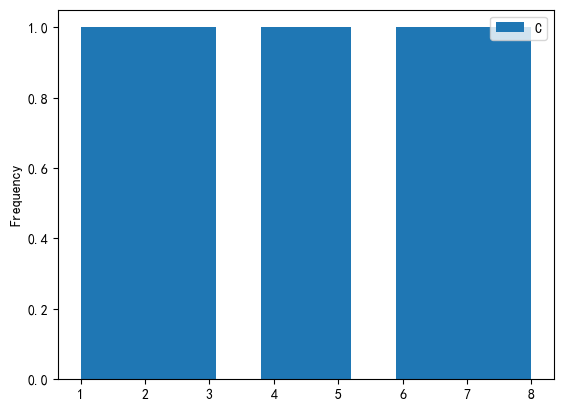
1 | |
结果:
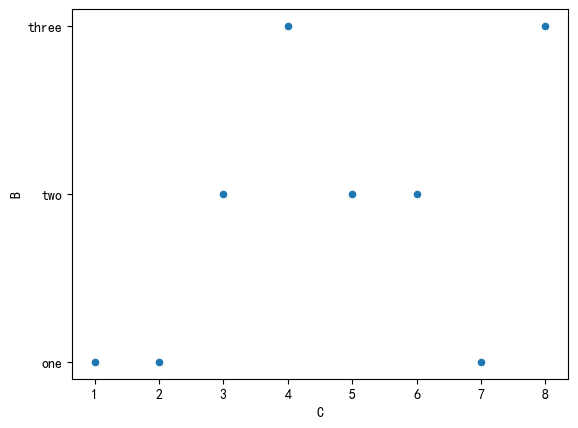
1 | |
结果: